
How are you doing compared to your peers on AI transformation?
This is the question that every board member and investor has for enterprise companies. Yet there is no standard, trusted answer.
That's because industry-accepted AI reports, to date, generally have two features: they depended entirely or almost entirely on survey data, and while some do industry analysis, they don't do peer group analysis on non-survey data.
They've done other things, sure. One in particular, the Stanford HAI's AI Index, relies on the most credible OSINT-based report in the landscape, patents, publications, investment flows, job postings, no self-reporting. At the AIDE Institute, we consider Stanford HAI the closest methodological relative to the AIDE Index. But it stops at the macro level. Its unit of analysis is countries, industries, and global trends, so it doesn't name or rank specific companies. It doesn't ask the question a board member or investor needs to answer: how does this specific company compare to its peers?
That is the gap we're zeroing in on. Twenty-one external reports. The most rigorous data institute in the world on one end, the most widely-cited consulting firms on the other. Not one produces a reliable peer group analysis of companies.
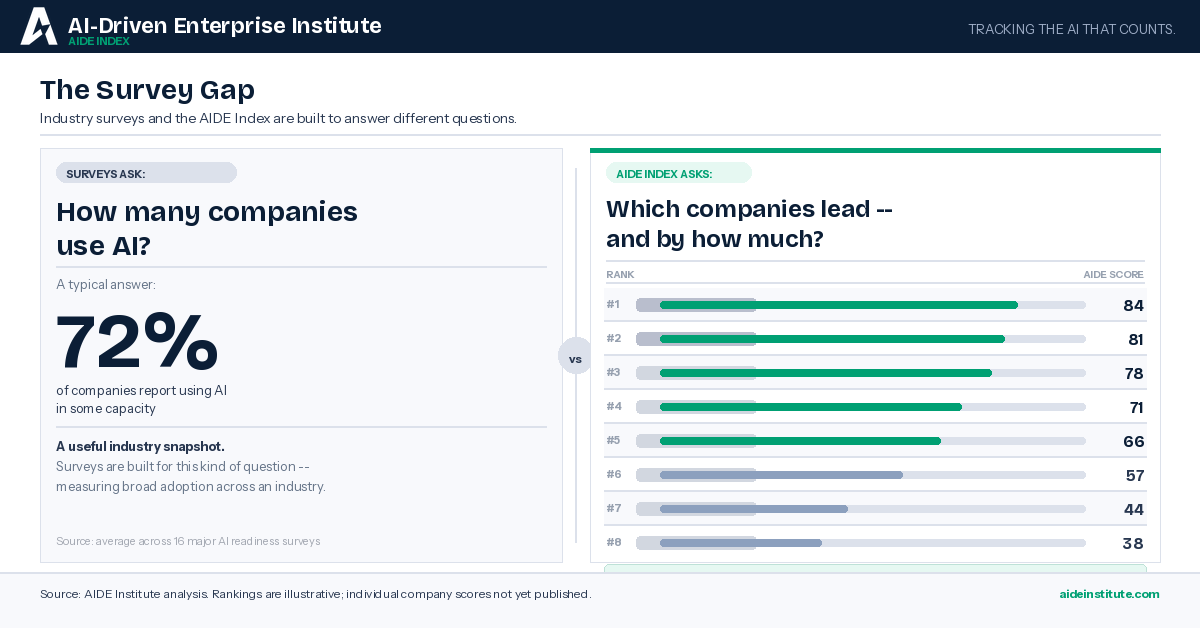
The AIDE Index scores every S&P 500 company individually, on a normalized 0–100 score built entirely from publicly observable behavior. No surveys. No self-reporting. No cooperation required from assessed companies. The same methodology applied to all 500.
You cannot get that output from a survey.
The method and the output are inseparable.
Why Surveys Aren't the Answer
There's a version of AI benchmarking that works like this: send every company a survey, ask them to rate their AI readiness on a 1–5 scale, collect the responses, and publish a ranking. It's fast. It's scalable. And it's not useful for benchmarking AI adoption and integration across enterprise companies.
The problem isn't that companies and their people lie, exactly. It's that the question itself is almost impossible to answer honestly.
What counts as "AI-ready"? Is a company that licensed Microsoft Copilot for 10,000 employees but has no one actually using it more AI-ready than one that quietly automated its entire claims processing pipeline with a custom model? If your definition of "production AI" starts at the boardroom and ends at the press release, you'll get one answer. If it starts on the factory floor and ends in the product, you'll get another.
Organizations don't overstate or understate AI readiness because they're dishonest. They partially do it because the domain moves faster than their internal vocabulary. The line between "piloting" and "in production" is rarely clean. The incentive to sound AI-forward to investors is real. So is the incentive to withhold when disclosure feels like a liability.
The result is data that reflects organizational narrative as much as operational reality. And narrative is not a reliable input for a benchmarking index.
The Gap Nobody Is Talking About
We reviewed 22 reports before building the AIDE Index. Every single one of them, from the Federal Reserve to McKinsey to Stanford HAI, has the same structural limitation: they don't rank individual companies.
That gap is not accidental. It's a consequence of the method. And understanding it is the clearest way to explain why the AIDE Index exists.
The survey category, McKinsey, Deloitte, BCG, IBM, Salesforce, NVIDIA, and the rest, has a well-documented limitation: companies self-report their AI adoption. Executives have real incentives to over-claim. Sounding AI-forward matters to investors, to talent, to press coverage. When McKinsey asks "what percentage of your organization uses AI regularly," the answer can reflect both reality and narrative.
Gathering data via open source collection methods (OSINT) doesn't have this problem. Job postings, patent filings, earnings call transcripts – those are observable signals, not declared ones. Nobody files a patent to impress a survey researcher.
Setting aside self-reporting bias, the survey category has a second problem: it aggregates. McKinsey tells you that 88% of companies are now using AI in at least one function. BCG tells you 54% of financial services leaders report redesigning workflows. These are useful findings. The BCG stat can tell you where the sector is. They do not tell you whether JPMorgan is ahead of Goldman, or by how much, or what the gap looks like. Company-level differentiation is outside what any survey can reliably produce.
What We Measure Instead
The AIDE Index doesn't ask companies anything. Every score is built entirely from publicly observable behavior. We only look at what companies demonstrably do with AI, not exclusively what they say they do.
This industry-standard approach is OSINT: Open Source Intelligence. All inputs are publicly available. No company has to cooperate with the assessment, disclose anything voluntarily, or even know they're being evaluated. The data exists in public records; we just collect and score it systematically.
Two collection methods work in parallel. In the first, it's all automated: structured pipelines that pull quantifiable signals from job postings, patent filings, SEC filings, earnings call transcripts, corporate websites, and annual reports. At scale, this produces a consistent, comparable dataset across all 500 companies.
In the second, we use structured AI Research Agents (ARA), AI-assisted tools that conduct structured, qualitative analysis of a wide variety of public sources: news coverage, conference presentations, investor day transcripts, engineering blogs, case studies. Where the automated pipelines count and score, the AI Research Agents read and classify.
The two methods do different jobs. One captures what leadership says in public: the marketing layer and the regulated disclosures. The other captures what the company is actually building. We read them against each other, and find the gap.
A Distinction Worth Making Explicit
Observable doesn't mean complete. Private AI deployments (internal tooling, proprietary models embedded in operations, anything not communicated publicly) are invisible to the AIDE Index by design. A company that has built world-class AI infrastructure but never talks about it publicly will score lower than its actual adoption warrants.
This is the honest boundary of any public-data methodology. We're transparent about it in the published methodology framework.
But it surfaces a more important distinction: the AIDE Index measures adoption posture, not AI impact. We can tell you what a company demonstrably does with AI, who they hire, what they patent, what their executives say publicly, how they position AI in investor communications. Whether that activity translates into financial returns is a separate empirical question.
It's an important one. The AIDE Institute is actively investigating the longitudinal correlation between adoption posture and business outcomes. But that research is a companion to the index, not a prerequisite for it. You can study adoption behavior before you've established causal links to performance, the same way you can measure exercise frequency before you've quantified its effect on longevity for any given individual.
Why Auditability Matters
The most underrated feature of an observable-data methodology is that it produces arguments, not just scores.
If a company's AIDE Index ranking surprises you, you can ask why. Because every score is built from traceable, publicly available signals, the answer exists. Point to a specific input, and we can have a real conversation about whether that signal was collected correctly, weighted appropriately, or is missing context.
That's not possible with a survey-based index. If a company self-reported a 4.2 out of 5, there's nothing to interrogate.
Transparency and auditability are design principles of the AIDE Index, not marketing claims. The full methodology is published. Every score can be traced from the final composite back through normalized pillar scores, raw pillar scores, channel-level signals, and individual data points. If you find an error, you can locate it precisely.
The index is only as useful as it is trustworthy. And trust in a ranking requires being able to check it.
This is the first of four posts breaking down the AIDE Index methodology. The full methodology framework will be published at aideinstitute.com after pending changes from our methodology review committee.
Image from Pixabay